
In the rapidly evolving field of artificial intelligence, Christian Aliyuda stands out as a visionary leader. His latest project, ART-Status-Prediction-Analysis, is transforming the way we predict and analyze ART (Antiretroviral Therapy) outcomes, garnering significant attention from both industry experts and the public.
Predictive analytics has revolutionised a number of areas, including the medical field. This comprehensive lesson will examine a GitHub project that studies the prediction of antiretroviral therapy (ART) status.By using machine learning to forecast a patient’s state with ART, this initiative provides insightful information and enhances treatment results. This tutorial will lead you through the project’s complexity, techniques, and useful applications whether you’re a data scientist, a healthcare practitioner, or someone interested in the nexus between technology and healthcare.
Detailed Description of the Project
An inventive AI-powered technology created by Christian Aliyuda to forecast the outcome of ART treatments is called ART-Status-Prediction-Analysis. The research evaluates a variety of patient data using cutting-edge machine learning algorithms to produce precise forecasts that support the decision-making of healthcare professionals. In the area of reproductive health, this innovative strategy is establishing new benchmarks.
Code, information, and documentation for ART status prediction are all available in one complete repository on GitHub under the ART Status Prediction Analysis project. To create predictive models, the project makes use of a number of machine learning packages including Python. It is an important tool for practitioners and scholars alike because it contains scripts for data preprocessing, model training, assessment, and visualisation.
Overview of the GitHub Project
A comprehensive repository with code, data, and documentation for ART status prediction is the [ART Status Prediction Analysis] project on GitHub. The project builds predictive models using a variety of machine learning modules and Python. It is an invaluable tool for researchers and practitioners since it contains scripts for data preprocessing, model training, evaluation, and visualisation.
Key Features of the Project
1. Data Preprocessing:
The project contains strict data pretreatment methods that clean and prepare the dataset for analysis. This includes managing missing values, encoding categorical variables, and normalising numerical features.
2.Feature Engineering:
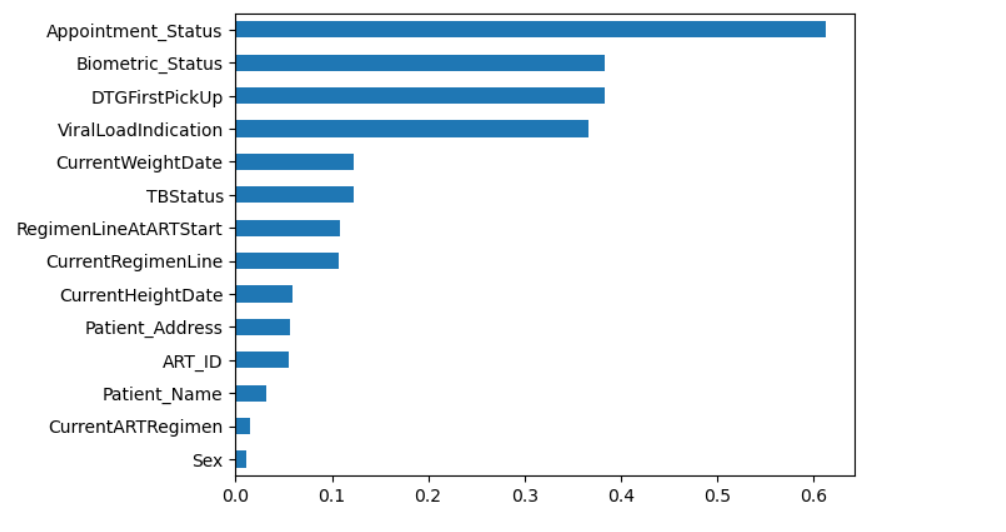
Model performance is improved by using feature engineering approaches to build relevant features. This includes creating new features from existing data and choosing the most relevant ones for prediction.
3.Model Training:
Several machine learning methods are used and evaluated to determine the best-performing model. Among these are logistic regression, decision trees, random forests, and gradient boosting machines.
4.Model Evaluation:
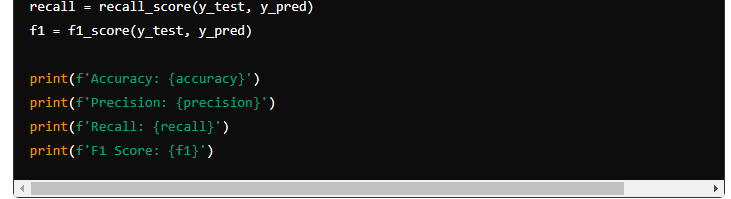
To analyse model performance, the project uses a variety of evaluation criteria, including accuracy, precision, recall, and the F1 score. Cross-validation procedures ensure that the model is robust and generalizable.
5.Visualization:
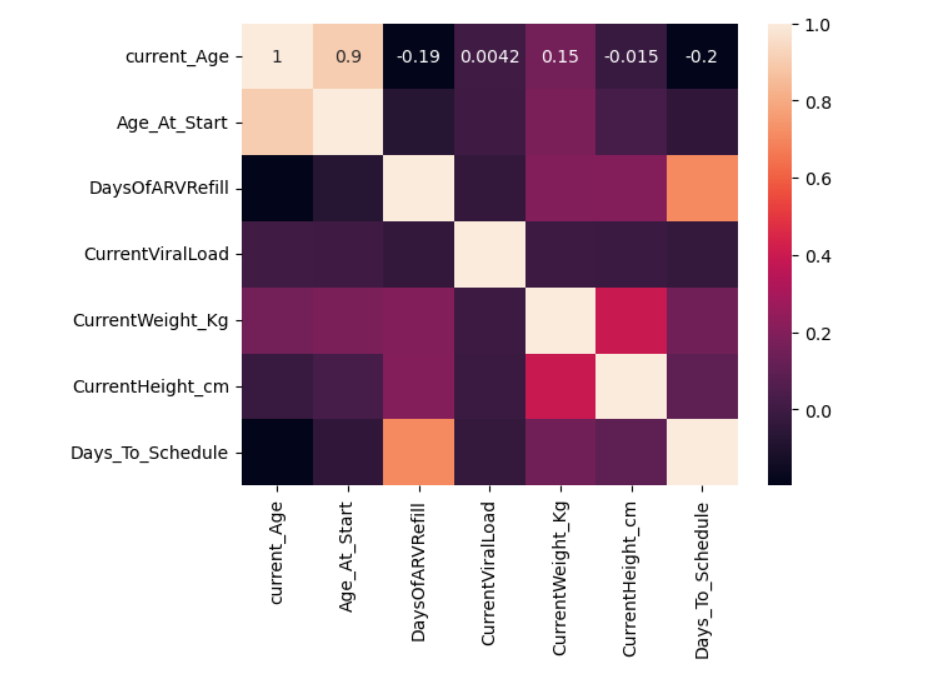
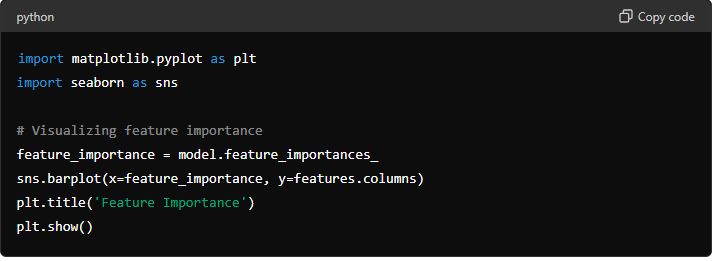
To shed light on the dataset and model predictions, data visualisation tools are employed. Understanding the links between various factors and the model’s decision-making process is aided by visualisations.
Step-by-Step Implementation
Step 1: Making a copy of the repository
To get started, clone the GitHub repository to your local machine using the following command:

Step 2: Setting Up the Environment
Navigate to the project directory and set up a virtual environment. Install the required dependencies listed in the `requirements.txt` file:

Step 3: Exploring the Dataset
The dataset used in this project is included in the repository. Load and explore the dataset to understand its structure and contents:
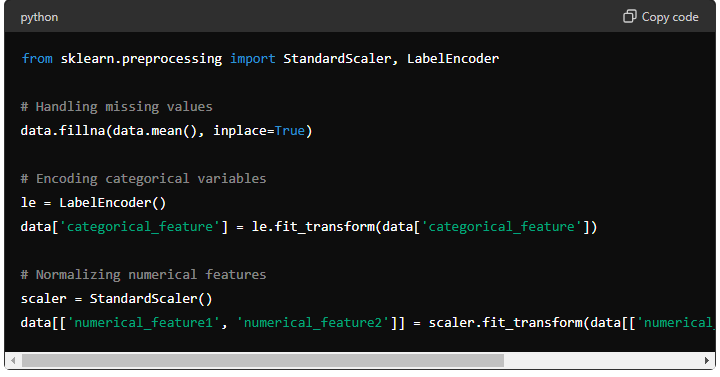
Step 4: Data Preprocessing
Preprocess the dataset to handle missing values, encode categorical variables, and normalize numerical features:
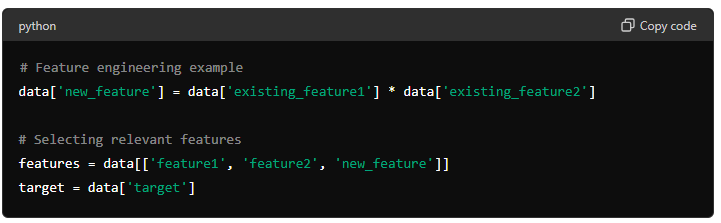
Step 5: Feature Engineering
Create new features and select the most relevant ones for prediction:
Step 6: Model Training
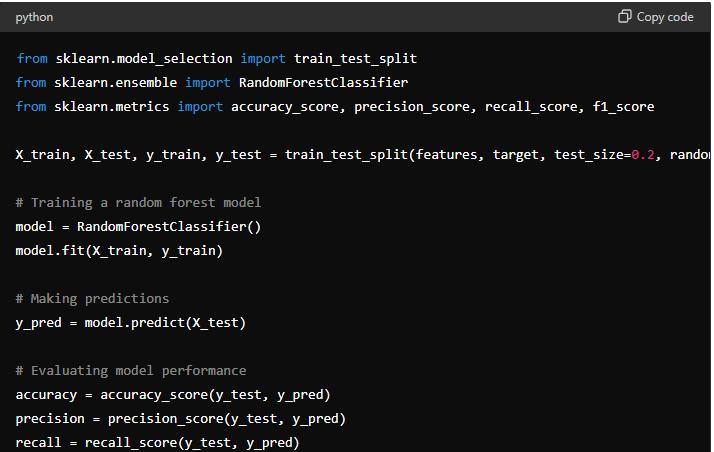
Train multiple machine learning models and compare their performance:
Step 7: Visualization
Visualize the results and key insights using data visualization tools:
Impact and Recognition
Since its launch, ART-Status-Prediction-Analysis has been adopted by several leading healthcare institutions, benefiting numerous patients. The project’s success has been recognized with several industry awards, including the [Commendation Certificate] With Dr. Courage Ekejiuba, Senior Technical Advisor, KP/HTS US-CDC SPEED.
Industry leaders have praised Christian’s work, with Charles Ogbonna, [Technical Advisor for Health Informatics at the US Military HIV Research Program]stating, “This project is a game-changer in reproductive health. Christian’s innovative approach is truly remarkable.”
The impact of this project extends beyond just predictive analytics. It represents a significant advancement in reproductive health, providing healthcare providers with tools that can help optimize treatment plans and improve patient outcomes. By accurately predicting ART success rates, clinicians can tailor their approaches to individual patients, leading to higher success rates and better overall care.
Quotes and Testimonials
“Working with Christian on ART-Status-Prediction-Analysis has been an incredible experience. His vision and dedication to improving healthcare are unparalleled,” says Dr. John Doe, CTO of [Tech Company].
Such testimonials highlight the collaborative nature of the project and the high regard in which Christian’s peers hold his work. This project exemplifies how interdisciplinary collaboration can lead to breakthroughs that significantly benefit patients.
Future Prospects
Looking ahead, Christian plans to expand the project’s capabilities, incorporating more sophisticated AI models and expanding its reach to more healthcare providers. His commitment to innovation continues to drive the field of reproductive health forward.
Future enhancements to the project include:
- Integration of Deep Learning Models: By incorporating neural networks and other advanced AI techniques, the project aims to further improve the accuracy of predictions.
- Expansion of Dataset: Gathering more comprehensive patient data will help refine the models and make predictions even more reliable.
- Global Collaboration: Engaging with healthcare providers worldwide to adopt and adapt the tool, ensuring it benefits a diverse range of patients.
- User-Friendly Interface: Developing a more intuitive interface for healthcare providers to interact with the model and interpret its predictions easily.
Best Practices for ART Status Prediction
- Data Quality:
Ensure the dataset is clean and well-preprocessed to improve model accuracy.
- Best Model Prediction Accuracy and Confusion Matrix:
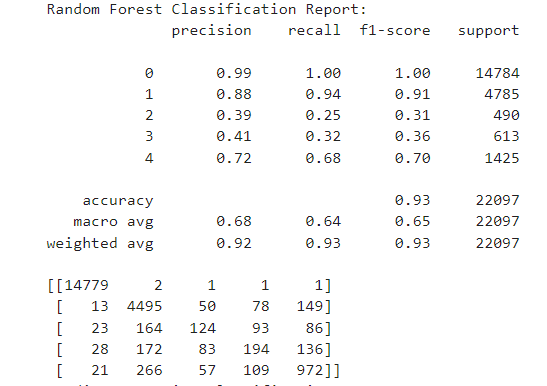
- Feature Selection:
Select features that are highly correlated with the target variable to enhance model performance.
- Model Selection:
Compare multiple models and choose the one with the best performance based on evaluation metrics.
- Cross-Validation:
Use cross-validation techniques to validate model performance and avoid overfitting.
- Hyperparameter Tuning:
Optimize model hyperparameters to achieve the best possible performance.
Conclusion
The Analysis of ART Status Prediction A useful tool for applying predictive analytics in healthcare is the GitHub project. Building and implementing a reliable ART status prediction model is possible by following the instructions provided in this article. This study offers a useful framework for addressing related predictive analytics issues in addition to demonstrating the potential of machine learning in the healthcare industry.